This article is part of IoT Architecture Series – https://navveenbalani.dev/index.php/articles/internet-of-things-architecture-components-and-stack-view/
In this article, we will build an IoT stack using open source software. Many vendors are building their own platform for realizing their end to end use cases. Our assessment shows there are at least 100 plus providers providing IoT stack in some form or the other.
Well, the first question that should come to your mind is why you need to build your own IoT stack when there are multiple platform providers providing the same functionality. We list some of the motivations below:
- Start-up providers – The start-up ventures eyes IoT as the hot cake in the market today and are at the forefront of building a cloud platform providing all kinds of cloud services, exploiting various gaps to solve industry-specific use cases.
- Hardware/Embedded software manufacturers – Many embedded software manufacturers, provides a cloud platform to store the data from the devices, like various OBD vehicle device manufacturers. The data from devices are aggregated in the cloud and analyzed using various tools and techniques.
- Internal evaluation and demos – Software service providers and System Integrators starting their IoT consulting journey or having an embedded software practice and looking at ways to analyze continuous streams of data and build predictive models as service offerings.
- Regulatory compliance – Industries that can’t use cloud services due to compliance are building their own in-house platforms for monitoring and condition maintenance activities.
Let’s look at our open source IoT stack. We have envisioned this using a popular set of integrated open source software providing high performance, high scalability, and low throughput capabilities.
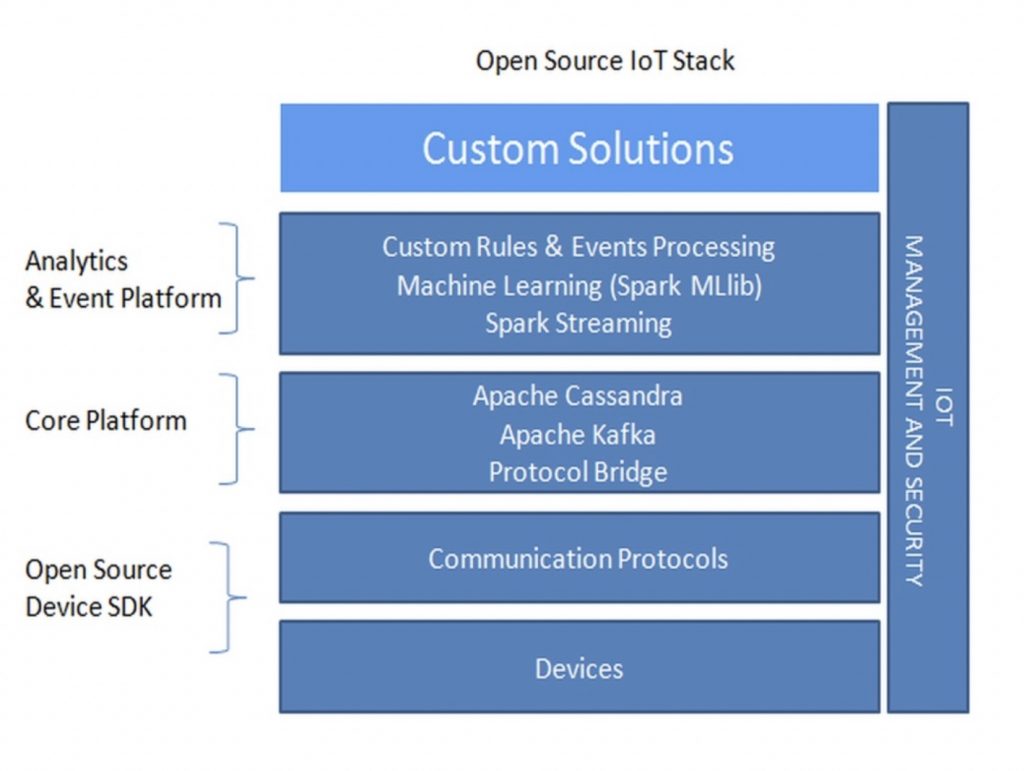
Open Source Device SDKs
The open source IoT platform provides support for wide variety of protocols like MQTT, AXMP, and HTTP protocol. For MQTT, we can leverage the Eclipse-based Paho library for connecting any device to the core platform or open source library like cyclon.js, which makes it easier to connect various devices using Node.js. We really liked the cyclone.js library and the extensions provided by the library to support various devices. The following is a snapshot of some of the devices supported by cyclon.js

Below is the sample code to connect to an analog sensor attached to pin “0” of a device, read the values and transmit the data to the cloud platform using MQTT protocol. It is just 20 lines of code.
var Cylon = require('cylon');
Cylon.robot({
connections:{
mqtt:{ adaptor:'mqtt', host:'mqtt://ourserver:port'},
arduino:{ adaptor:'firmata', port:'/dev/ttyACM0'}
},
devices:{
allimit:{ driver:'mqtt', topic:'llimit', adaptor:'mqtt'},
aulimit:{ driver:'mqtt', topic:'ulimit', adaptor:'mqtt'},
sensor:{ driver:"analogSensor", pin:0, upperLimit:900, lowerLimit:100}
},
work:function(my)
my.sensor.on("upperLimit",function(val){
my.aulimit.publish(val);
});
my.sensor.on("lowerLimit",function(val){
my.allimit.publish(val);
});
}
}).start();
Protocol Bridge
This service acts as a router or gateway for converting incoming protocols to the protocol supported by the core IoT platform. For instance, if the core platform has Apache Kafka setup to process messages and the client communicates using MQTT, then we could write a MQTT server that will receive the data and convert it into the format that Apache Kafka understands. The protocol bridge takes care of sending messages to Apache Kafka over specified topics and determines which partition the message is to be sent.
Apache Kafka
Apache Kafka service provides us with a highly scalable, low latency, fast and distributed publish-subscribe messaging system.
Apache Kafka was developed at LinkedIn. The following link is an excellent blog which talks about how Kafka was used and what problems it solved at LinkedIn – http://www.confluent.io/blog/stream-data-platform-1/. Though Kafka was not designed as a typical messaging system. it found its roots in many applications, which required high throughput, distributed messaging framework.
Similar to any publish-subscribe messaging system; Kafka maintains feeds of messages in categories called topics. Producers publish data to topics and consumers subscribe to topics to read messages. In our case, the publisher is the protocol bridge that posts the messages (data from devices) on specified topics. Topics are further partitioned and replicated across nodes. For the connected car use case, we use the main controller device id (the telematics device id or the hardware device id connected to OBD port) as the partition id to ensure all messages from the same device id ends up in the same partition.
Kafka can retain messages after the specified time interval has elapsed, unlike other messaging systems that delete messages as soon as they are consumed. Going through the entire capabilities of Kafka and its working would require a book in itself. We suggest going through the document http://kafka.apache.org/documentation.html, which provides an excellent source of information on Apache Kafka.
Cassandra
We use Apache Cassandra for storing the continuous stream of data coming from devices. We create a Kafka consumer that listens to a specified topic, consumes the message and stores the message in one of the Cassandra tables.
We use Cassandra for historical data analysis to gain insights on various usages, aggregations, and computations, build correlations, and to develop our machine learning models iteratively for anomaly detection and predictive analytics. For developing machine learning models, we use Spark Core libraries for connecting to our Cassandra tables and perform data transformation and Spark MLlib libraries for developing machine learning models.
Apache Spark Streaming
Apache Spark streaming component from Apache Spark project adds real-time data stream processing and data transformation for further processing by systems. We chose Apache Spark as it’s an ultra-fast in-memory data processing framework. It provides a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. Apache Spark streaming supports real-time processing as well as batch updates on top of Spark engine, which makes it the perfect choice for applications which requires responding to real-time events and batch processing via Hadoop jobs for complex data analysis. Apache Spark streaming component provides first class integration with Apache Kafka using the Spark Stream Kafka module (spark-streaming-kafka_2.10 version was the latest when we tested the integration). Details of integration are available at this link – http://spark.apache.org/docs/latest/streaming-kafka-integration.html. There are two approaches – Receiver based approach, which uses Kafka high-level consumer APIs to consume the messages from a specified topic. This is the old way and requires some workaround to ensure there is no data loss during failures. The other approach is using a direct approach which periodically queries Kafka for the latest offsets in each topic + partition and uses the offset ranges to process data in batches. We have used direct approach for integration and recommend using the same. Once integrated, the streams of data start flowing in Apache Spark Steaming layer, where you can do real-time transformation, filtering and store the data for further analysis or invoke machine learning models (like streaming linear regression).
Apache Spark MLlib
Apache Spark MLlib service is used to build machine learning models or combine multiple machine learning models using a standardized API. Building a machine learning models requires a series of step as discussed earlier –like cleansing and transformation, creating feature vectors, correlation, splitting up data in training and test sets, selecting algorithms for building up required models (prediction, classification, regression, etc.) and iteratively training the model for required accuracy. Typically multiple tools are required to carry out the tasks describe earlier and using Spark APIs and ML libraries everything can be developed iteratively in a single environment.
Custom Rules and Events
For custom rules and events, we create custom application code which is executed as part of the spark streaming flow and triggers the required action based on the incoming data. Apache Zeppelin project can be used to quickly build an interactive data analytics dashboard. Zeppelin has built-in support for Spark integration and SparkSQL. The project is under incubation and evolving.
Implementation Overview
The implementation steps of realizing the connected car or elevator use case using the open source IoT stack is pretty much the same that we described earlier for IoT stacks from Microsoft, Amazon, and IBM, and it’s just a matter of replacing services provided by these vendors with open source offerings described above. Though we did not design a complete IoT stack, as we left out the device management capabilities, it still provides a decent perspective of building an end-to-end IoT solution using open source products. The device management and security aspect require developing custom components to meet the requirements. We leave this as an exercise for you to bring out the best of open source platforms and envision a complete IoT stack.
This completes the article series.

{kind=link}