In general, semantics is the study of meaning. (The word “semantic” comes from the Greek semantikos, or “significant meaning,” derived from sema, or “sign.”) Semantic Web technologies help separate meanings from data, document content, or application code, using technologies based on open standards. If a computer understands the semantics of a document, it doesn’t just interpret the series of characters that make up that document: it understands the document’s meaning.
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. You can think of the Semantic Web as an efficient way to represent data on the World Wide Web, or as a database that is globally linked, in a manner understandable by machines, to the content of documents on the Web. Semantic technologies represent meaning using ontologies and provide reasoning through the relationships, rules, logic, and conditions represented in those ontologies.
Technologies that make up the Semantic Web
To represent the Semantic Web, you’ll use the following technologies:
- A global naming scheme (URIs)
- A standard syntax for describing data (RDF)
- A standard means of describing the properties of that data (RDF Schema)
- A standard means of describing relationships between data items (ontologies defined with the OWL Web Ontology Language)
Let’s take a closer look at these technologies.
A global naming scheme: URIs
A URI is simply a Web identifier, like the strings starting with http or ftp that you often see on the World Wide Web. Anyone can create a URI, and the ownership of URIs is clearly delegated, so they form an ideal base technology on top of which to build a global Web. In fact, the World Wide Web is such a thing: anything that has a URI is considered to be “on the Web.” Every data object and every data schema/model in the Semantic Web must have a unique URI.
A Uniform Resource Locator (URL) is a URI that, in addition to identifying a resource, provides a means of acting upon or obtaining a representation of that resource by describing its primary access mechanism or network location. For example, the URL http://www.webifysolutions.com is a URI that identifies a resource (Webify Solutions’ home page) and implies that a representation of that resource (such as the home page’s current HTML code, as encoded characters) is obtainable through HTTP from a network host named www.webifysolutions.com.
A Uniform Resource Name (URN) is a URI that identifies a resource by name in a particular namespace. You can use a URN to talk about a resource without implying its location or how to dereference it. For example, the URN urn:ISBN:1-0-7666-98-0 is a URI that, like an ISBN book number, allows one to talk about a book, but doesn’t suggest where and how to obtain an actual copy of it.
A standard syntax to describe data: RDF
RDF is a specification that defines a model for representing the world, and a syntax for serializing and exchanging that model. The W3C has developed an XML serialization for RDF. RDF XML is the standard interchange format for RDF on the Semantic Web, although it is not the only format. For example, Notation3 is an excellent plain text alternative serialization to RDF XML.
RDF provides a consistent, standardized way to describe and query Internet resources, from text pages and graphics to audio files and video clips. It offers syntactic interoperability, and provides the base layer for building a Semantic Web. RDF defines a directed graph of relationships. These are represented by object-attribute-value triples — that is, an object O has an attribute A with the value V.
Listing 1 provides an example of RDF XML.
Listing 1. An RDF XML example
<?xml version=”1.0″?>
<rdf:RDF xmlns:rdf=”http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:contact=”http://www.w3.org/2000/05/contact#”>
<contact:Company rdf:about=”http://www.w3.org/Organization/contact#WebifySolutions”>
<contact:name>Webify Solutions</contact:name>
<contact:mailbox rdf:resource=”mailto:info@webifysolutions.com”/>
<contact:phone>1-800-4WEBIFY</contact:phone>
</contact:Company>
</rdf:RDF>
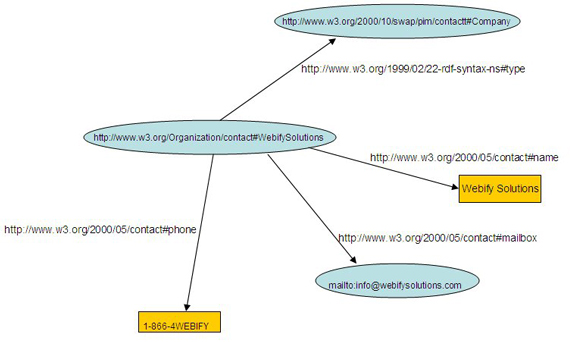
The piece of RDF in Listing 1 basically makes a statement about a resource, which in this case is the company http://www.w3.org/Organization/contact#WebifySolutions. The company can be identified by the URI http://www.w3.org/Organization/contact#WebifySolutions; its name is Webify Solutions, its e-mail address is info@webifysolutions.com, and its phone number is 1-800-4WEBIFY.
The directed graph of relationships illustrated in Figure 1 represents this.
Figure 1. RDF graph that describes the contact details of Webify Solutions

A standard means to describe the properties of data: RDF Schema
RDF Schema is a semantic extension of RDF. It provides mechanisms to describe groups of related resources and the relationships between those resources.
The RDF Schema class and property system is similar to the type systems of object-oriented programming languages such as the Java language. RDF differs from many such systems. Rather than define a class in terms of the properties of its instances, the RDF vocabulary description language describes properties in terms of which classes of resource that the properties apply to.
Both RDF and RDF Schema are based on XML and XML Schema. The existence of standards for describing data (RDF) and data attributes (RDF Schema) enables the development of a set of readily available tools to read and exploit data from multiple sources. The degree to which different applications can share and exploit data is sometimes called syntactic interoperability. The more standardized and widespread these data manipulation tools are, the higher the degree of syntactic interoperability, and the easier and more attractive it becomes to use the Semantic Web approach as opposed to a point-to-point integrated solution.
A standard means to describe relationships between data items: Ontologies that use the OWL Web Ontology Language
Before multiple applications can truly understand data — and treat it as information — semantic interoperability is required. Syntactic interoperability is all about parsing data correctly. It requires mapping between terms, which in turn requires content analysis.
This content analysis requires formal and explicit specifications of domain models, which define the terms used and their relationships. Such formal domain models are sometimes called ontologies. Ontologies define data models in terms of classes, subclasses, and properties.
With the W3C-recommended OWL Web Ontology Language, you can express ontologies. OWL (Ontology Working Language) adds more vocabulary to describe properties and classes than RDF or RDF Schema: among other things, it can describe relations between classes (such as disjointness), cardinality (for example, “exactly one”), equality, richer typing of properties, and characteristics of properties (such as symmetry).
The OWL Web Ontology Language is designed for use by applications that need to process the content of information rather than just presenting information to humans. OWL facilitates greater machine interpretability of Web content than that supported by XML, RDF, and RDF Schema by providing additional vocabulary along with formal semantics. OWL has three sublanguages: in order of decreasing expressiveness, they are OWL Full, OWL DL, and OWL Lite.
- The OWL Web Ontology Language taken as a whole is called OWL Full. OWL Full uses all OWL language primitives and allows combinations of those primitives in arbitrary ways with RDF and RDF Schema. OWL Full is fully upward-compatible with RDF, both syntactically and semantically: any legal RDF document is also a legal OWL Full document. It is unlikely that any reasoning software can support every feature of OWL Full, as it offers maximum expressiveness and the syntactic freedom of RDF with no computational guarantees.
- OWL DL supports those users who want maximum expressiveness without losing computational completeness. OWL DL is a sublanguage of OWL Full language constructs with restrictions such as type separation (for example, a class can not also be an individual or property, and a property cannot also be an individual or class).
- OWL Lite supports those users primarily needing a classification hierarchy and simple constraint features. The advantage of this language is that it is both easier to understand and easier to implement than the other two; however, it restricts expressivity. For example, while OWL Lite supports cardinality constraints, it only permits cardinality values of 0 or 1.
Examples of ontologies include catalogs for online shopping sites like Amazon.com, domain-specific standard terminology like UNSPSC (a terminology used for products and services), or various taxonomies on the Web, like the “My Yahoo” categories.
Next, I’ll take a closer look at the components of OWL.
Components of OWL Web Ontology Language
The basic components of OWL include classes, properties, and individuals, which you’ll examine in turn.
Classes
Classes are the basic building blocks of an OWL ontology. A class is a concept in a domain. Classes usually constitute a taxonomic hierarchy (a subclass-superclass hierarchy).
Classes are defined using the owl:Class element. OWL comes with two predefined classes: owl:Thing and owl:Nothing. owl:Thing is the most general class, which contains everything; owl:Nothing is an empty class. Every class you define is a subclass of owl:Thing and a superclass of owl:Nothing. Examples of classes in a banking domain might include Account or Customer.
Listing 2 presents an example of an OWL class.
Listing 2. OWL class example
<owl:Class rdf:ID=”SavingsAccount”>
<rdfs:subclassOf rdf:resource=”#Account”/>
</owl:Class>
The code in Listing 2 specifies that SavingAccount is a class that is a subclass of Account.
OWL supports six main ways to describe classes. The simplest of these is a named class. The other types are intersection classes, union classes, complement classes, restrictions, and enumerated classes. Listing 2 illustrates two of these ways of describing classes: a restriction defines SavingAccount as a subclass of the named class Account.
Properties
Properties have two main categories:
- Object properties, which relate individuals to other individuals.
- Datatype properties, which relate individuals to datatype values, such as integers, floats, and strings. Owl makes use of XML Schema for defining datatypes.
A property can have a domain and range associated with it. Each property can be be put into one of the following categories:
- Functional: For a given object, the property takes only one value. Examples include a person’s age, height, or weight.
- Inverse functional: Two different individuals cannot have the same value. For example, the bankNumber or SSN properties are unique for each person.
- Symmetric: If a property links A to B, then one can infer that it links B to A. Examples of symmetric properties includes “is sibling of” or “is same as”.
- Transitive: If a property links A to B and B to C, then one can infer that it links A to C. For example, if A is taller than B and B is taller than C, then A is taller than C.
You can apply various restrictions to classes and properties. For example, cardinality restrictions specify the number of relationships that a class of individuals can participate in.
Individuals
Individuals are instances of classes, and properties can relate one individual to another. For example, you might describe an individual named Smith as an instance of the class Person, and might use the property hasEmployer to relate Smith to the individual Webify Solutions, signifying that Smith is an employee of Webify Solutions.
Listing 3 offers an example of an OWL individual.
Listing 3. An OWL individual
| <owl:Thing rdf:about=”SmithAccount”> <rdfs:type=”#Account”/> </owl:Class> |
rdf:type is an RDF property that ties an individual to a class of which it is a member. Listing 3 indicates that SmithAccount is an instance of type Account.
Figure 2 illustrates the basic building blocks of an OWL ontology.
Figure 2. OWL ontology that describes the Webify Solutions organization

IT systems organize meanings using relational data models, flat files, object-oriented models, or proprietary data models. From time to time, the demands of changing business needs require that you add new entities and relationships to the relational data models or object-oriented models.
Moreover, if an organization uses many applications provided by various vendors, you might replicate the same model across application databases. Say, for instance, that a banking firm provides a variety of products to serve various types of customers. A corporate customer might require a fraud detection facility, for instance, while a normal customer might use only online banking functionality. Normally, several vendors provide the applications for the bank, but each application replicates the same common information — accounts, customers, and so on — in an application-specific database. As the organization adds products to meet ever-growing business needs, the same redundant information becomes scattered around the enterprise.
A number of services definitely are common to all the applications being developed — viewing bank transactions and wire transfers, for instance. Each of these services is also replicated in a fashion specific to each application, leading to point-to-point integration.
If the bank adapts an ontology-driven approach, it can capture and represent its total product knowledge in a language-neutral form and deploy the knowledge in a central repository. With this shared, adapted ontology, the organization can provide a single, unified view of data across its applications. This unified view allows for precise retrieval of information and seamless enterprise integration, as business processes and various data sources can map to each other through a common meta-model. Thus, the shared ontology eliminates point-to point integration and simplifies application integration, reducing data redundancy and providing the same semantic meaning across applications, which eases the bank’s maintenance and upgrades.
Benefits of the Semantic Web to the World Wide Web
The World Wide Web is the biggest repository of information ever created, with growing contents in various languages and fields of knowledge. But, in the long run, it is extremely difficult to make sense of this content. Search engines might help you find content containing specific words, but that content might not be exactly what you want. What is lacking? The search is based on the contents of pages and not the semantic meaning of the page’s contents or information about the page.
Once the Semantic Web exists, it can provide the ability to tag all content on the Web, describe what each piece of information is about and give semantic meaning to the content item. Thus, search engines become more effective than they are now, and users can find the precise information they are hunting. Organizations that provide various services can tag those services with meaning; using Web-based software agents, you can dynamically find these services on the fly and use them to your benefit or in collaboration with other services.
Role and value of semantic technology in SOAs
To properly model and manage a service-oriented architecture (SOA), enterprise architects must maintain active representations of the services available to the enterprise. Specifically, to discover and organize their services, the architects must use best practices that model and assemble services using metadata, encapsulate business logic in metadata for dynamic binding, and manage with metadata. Ontologies provide a very powerful and flexible way to aggregate, visualize, and normalize this service metadata layer.
An ontology is a network of concepts, relationships, and constraints that provide context for data and information as well as processes. Ontologies enhance service discovery, modeling, assembly, mediation, and semantic interoperability. They improve the way people browse, explore, and interact with complex metadata information spaces. A business ontology is a formal specification of business concepts and their interrelationships that facilitates machine reasoning and inference. A business ontology ties systems together using metadata, much as a database ties together discrete pieces of data. This abstraction provides agility and flexibility, as interfaces can be changed and new resources and subscribers added easily, even while the system is running.
Semantics are the future of service-oriented integration. Semantic technologies provide an abstraction layer above existing IT technologies, one that enables the bridging and interconnection of data, content, and processes across business and IT silos. Finally, from the human interaction perspective, semantic technologies add a new level of semantic portals that provide far more intelligent, relevant, and contextually aware interactions than those available with the traditional point-to-point integration approach for portal-based information delivery.
Conclusion
In this article, you went through the core standards that make up the Semantic Web’s technologies and learned why organizations might want to adopt those technologies. With Semantic Web technologies, organizations can provide a single, unified view of data across their applications, which allows for precise retrieval of information, simplifies enterprise and SOA integration, reduces data redundancy, and provides uniform semantic meaning across applications. All this eases development, maintenance, and upgrades across the enterprise.
This article of mine was first published by IBM DeveloperWorks in 2005 .All rights retained by IBM and the author.



{kind=link}