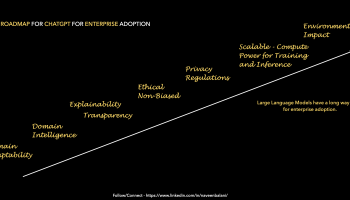
Responsible AI, in simple words, is about developing explainable, ethical, and unbiased models. For instance, Google has published its AI principles – https://ai.google/principles/, which discusses this subject in detail. Similarly, Microsoft has published its AI principles at https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/innovate/best-practices/trusted-ai. These key AI principles should be included as part of the design and development of large language models, as millions of users would view the output out of the AI systems. However, with ChatGPT, many instances fall shorts of these AI principles.
- Lack of Trust – Responses can sound plausible even if the output is false (Reference – https://venturebeat.com/ai/the-hidden-danger-of-chatgpt-and-generative-ai-the-ai-beat/). You can’t rely on the output and need to verify it eventually.
- Lack of Explainability on how the responses are derived. For instance, if the responses are created from multiple sources, list the source, and give attributions. There might be an inherent bias in the content and how this would be removed before training or filtered from the response. The response can be generated from multiple sources, and was there any priority source that was preferred to generate the response. Currently, ChatGPT doesn’t provide any explainability on the answers.
- Ethical aspects – One of the examples is around code generation. As part of the generated code, there are no attributions to the original code, author, or license details. For instance, Open source has many licenses (https://opensource.org/licenses/); some might be restrictive. Also, were there any priority open-source repositories preferred during training (or filtering outputs) over others. Questions about the code’s security, vulnerability, and scalability must also be addressed. It is ultimately the accountability and responsibility of the developer to ensure that the code is reviewed, tested, secure, and follows their organization’s guidelines. All the above details should be transparent and addressed. For instance, if customers ask for Certification of Originality for their software application (or if there is a law in the future), this might be a challenge with AI-generated code unless the above is considered.
- Fairness in responses – An excellent set of principles and an AI Fairness Checklist are outlined in the Microsoft paper – https://query.prod.cms.rt.microsoft.com/cms/api/am/binary/RE4t6dA. Given that ChatGPT is trained using internet content (a massive 570 GB of data sourced from Wikipedia, research articles, websites, books, etc.), it would be interesting to see how many items from the AI Fairness Checklist are followed. For instance, the content might be biased and have limitations. The human feedback used for data labeling might not represent the wider world (Reference – https://time.com/6247678/openai-chatgpt-kenya-workers/). These are some of the reported instances, but many might be undiscovered. Large-scale language models should be designed fairly and inclusively before being released. We should not say that the underlying content was biased; hence, the trained mode inherited the bias. We now have an opportunity to remove those biases from the content itself as we train the models.
- Confidentiality and privacy issues – As ChatGPT learns from interactions, there are no clear guidelines on what information would be used for training. If you interact with ChatGPT and end by sharing confidential data or a customer code for debugging, would that be used for training ?. Can we claim ChatGPT is GDPR compliant?
I have listed only some highlights above to raise awareness around this important topic.
We are at a junction where will see many AI advancements like ChatGPT, which millions of users would use. As these large-scale AI models are released, we must embed Responsible AI principles while releasing the models for a safer and trusted environment.



{kind=link}