
As AI evolves, sustainability must become a core principle of its development and deployment. Whether you’re interacting with AI models through APIs like OpenAI or Gemini, fine-tuning existing models, or building AI models from scratch, impactful strategies can make AI more sustainable—through practical, measurable actions. These are some of the strategies that different roles—developers, data scientists, engineers, and application architects—can use to contribute meaningfully to the sustainability of AI.
1. Calling APIs: OpenAI, Gemini Models, and More
If you’re leveraging large AI models like OpenAI’s or Gemini’s via APIs, the sustainability impact often comes from the volume of requests and how they are managed. Here’s how to make a tangible difference:
- Prompt Caching: Instead of calling an AI model repeatedly for similar responses, cache prompts and their outputs. This reduces the number of API calls, thus decreasing the computational load and energy consumption. By caching effectively, you can significantly reduce redundancy, especially in high-volume applications, making a powerful impact on energy efficiency.
- Compression Techniques: Compressing data before sending it to the API can save bandwidth and reduce energy usage. This is particularly important when passing large text blocks or multi-part prompts. Reducing payload size cuts down processing requirements directly, saving both computational energy and cost.
- Optimizing API Calls: Batch operations when possible and avoid unnecessary API calls. Use conditional checks to determine whether an AI call is truly needed or if a cached response would suffice. Eliminating redundant processing reduces emissions while also improving response times.
2. Fine-Tuning Models: Efficient Training Strategies
For data scientists and engineers fine-tuning models, sustainability starts with smarter planning and cutting-edge techniques:
- Parameter-Efficient Fine-Tuning: Techniques like LoRA (Low-Rank Adaptation) allow you to modify only a small number of parameters instead of the entire model, reducing computational resources and energy consumption without sacrificing performance.
- Energy-Aware Hyperparameter Tuning: Use automated tools to find optimal training parameters that minimize energy usage. By intelligently reducing the search space, hyperparameter tuning becomes significantly more efficient, saving valuable resources.
- Model Distillation: If a large model is being fine-tuned, consider distilling it into a smaller, more efficient version after training. This ensures similar performance during inference with far lower energy requirements, leading to more sustainable deployments.
3. Building AI Models from Scratch: Sustainable Development
When building models from scratch, sustainability should guide every decision from inception:
- Select Energy-Efficient Architectures: Some architectures are inherently more energy-intensive than others. Carefully evaluate the energy footprint of different architectures and choose one that provides the best performance-to-efficiency ratio.
- Data Efficiency: Reduce redundancy in training data. Use data deduplication and active learning to ensure only the most informative examples are used, which minimizes the training duration and associated energy consumption.
- Green Training Practices: Schedule training jobs during times when your cloud provider uses renewable energy. Many providers now offer transparency about energy sources and options to optimize for sustainability, helping you further reduce your carbon footprint.
4. Holistic Approach to Software Emissions
AI is only one part of a broader software ecosystem, and achieving true sustainability requires a holistic perspective:
- Full Stack Optimization: Optimizing the AI model is only part of the solution. Focus on the entire stack—including frontend performance, backend services, and data storage. Efficient code, reduced memory usage, and fast load times not only improve user experience but also reduce the overall energy footprint. For user-facing generative AI apps, optimizing prompts to be concise reduces computation and saves energy, especially at scale.
- Auto-Scaling and Carbon Awareness: When deploying generative AI applications, use auto-scaling infrastructure that grows and shrinks based on demand, thus reducing energy waste. Additionally, incorporate carbon-aware scheduling to run compute-heavy tasks during times of lower grid emissions, aligning with periods of renewable energy availability.
- Carbon-Aware Development Practices: Adopt practices such as moving workloads to regions with cleaner energy and reducing the carbon impact of data storage by using efficient storage formats and deleting unused data. Integrate these considerations into every stage of development to create end-to-end sustainable software.
- Continuous Monitoring and Measurement: Deploy tools to monitor the carbon footprint of your application in real-time. Measure software emissions using metrics like Software Carbon Intensity (SCI) to quantify and track the environmental impact. Regular monitoring allows for ongoing optimizations, ensuring that your AI systems remain sustainable as usage patterns evolve.
By embracing sustainability throughout every stage—from API usage to building models and deploying applications—we can significantly reduce the environmental impact of AI. Sustainability is not a one-time effort but a continuous, proactive commitment to making intelligent decisions that lead to truly greener AI systems with lasting impact.







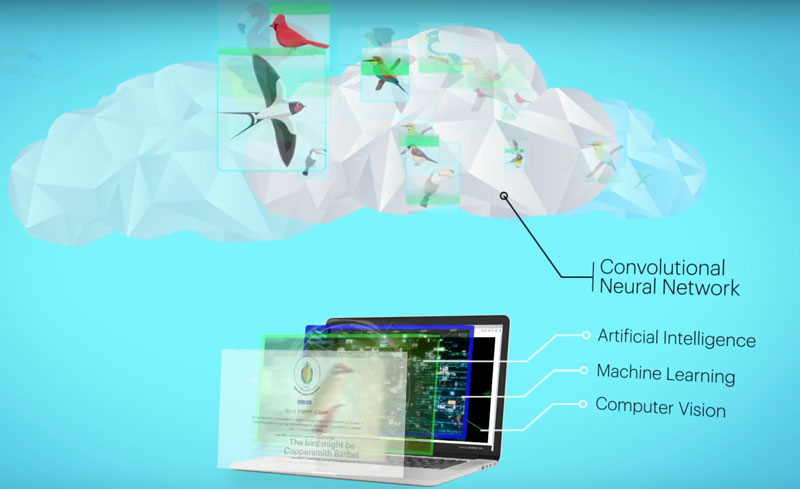
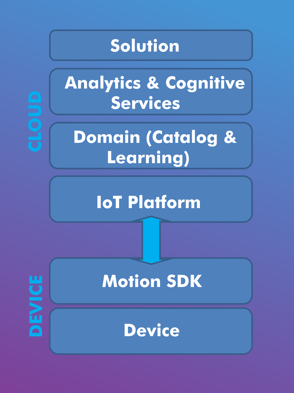
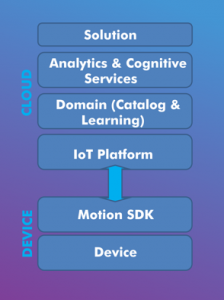 For an architecture stack perspective, you have the low powered embedded device installed inside the ball or embedded as part of the design and manufacturing process, its provides at least 6 Axis combo sensor for accelerometer and gyroscopes reading to identify any movement in 3d space. A Motion SDK is installed on top of the device to identify any movements in general and communicate the reading to the cloud. In cloud, we have the learning model or the training data. Basically, we would ask an expert batsman to bat and play various expert strokes like cover drive etc. and record their movements from sensors (bats/pads etc) as well as visuals (postures etc), this would be used as the training / test data and comparison would be made against it. As we are comparing 3D models, machine learning approaches like dimension reduction can be employed ( and many new innovation approaches) to compare two motion and predict the similarity. Similar training data is captured from an expert baller, along with other conceptual information like hand movements, pitch angles etc.
For an architecture stack perspective, you have the low powered embedded device installed inside the ball or embedded as part of the design and manufacturing process, its provides at least 6 Axis combo sensor for accelerometer and gyroscopes reading to identify any movement in 3d space. A Motion SDK is installed on top of the device to identify any movements in general and communicate the reading to the cloud. In cloud, we have the learning model or the training data. Basically, we would ask an expert batsman to bat and play various expert strokes like cover drive etc. and record their movements from sensors (bats/pads etc) as well as visuals (postures etc), this would be used as the training / test data and comparison would be made against it. As we are comparing 3D models, machine learning approaches like dimension reduction can be employed ( and many new innovation approaches) to compare two motion and predict the similarity. Similar training data is captured from an expert baller, along with other conceptual information like hand movements, pitch angles etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}